【Java数据结构与算法】树结构应用
大顶堆和小顶堆图解说明
堆排序基本介绍
-
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),她也是不稳定排序。
-
堆是具有以下性质的完全二叉树:每个节点的值都大于或等于其左右子节点的值,称为大顶堆(注意:没有要求节点的左子节点的值和右子节点的值的大小关系)。
-
每个节点的值都小于或者等于其左右子节点的值,称为小顶堆。
-
大顶堆举例说明:

我们对堆中的节点按层进行编号,映射到数组中就是下面的样子:
大顶堆特点:
arr[i]>=arr[2*i+1] && arr[i]>=arr[2*i+2]i从0开始编号,对应第几个节点。 -
小顶堆举例说明:
小顶堆:
arr[i]<=arr[2*i+1] && arr[i] <= arr[2*i+2];i从0开始编号,对应第几个节点。 -
一般升序采用大顶堆,降序采用小顶堆。



堆排序的思路图解
堆排序基本思想
- 将待排序序列构造成一个大顶堆(数组)。
- 此时,整个序列的最大值就是堆顶的根节点。
- 将其与末尾元素进行交换,此时末尾就为最大值。
- 然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列。
可以看到在构建大顶堆的过程中,元素的个数逐渐减少,最后就得到一个有序序列了。
堆排序步骤图解说明
要求:给你一个数组{4,6,8,5,9},要求使用堆排序法,将数组升序排序。
步骤1、构造初始堆
原始数组[4,6,8,5,9]
-
假设给定无序序列结构如下:
-
此时我们从最后一个非叶子节点开始(arr.length/2-1=5/2-1=1,也就是下面的6节点),从左至右,从下至上进行调整。
-
找到第二个非叶子节点4,由于[4,9,8]中9元素最大,则4和9交换。
-
这时,交换导致[4,5,6]结构出现混乱,继续调整,[4,5,6]中6最大,交换4和6。
-
此时我们就将一个无序序列构造成一个大顶堆。

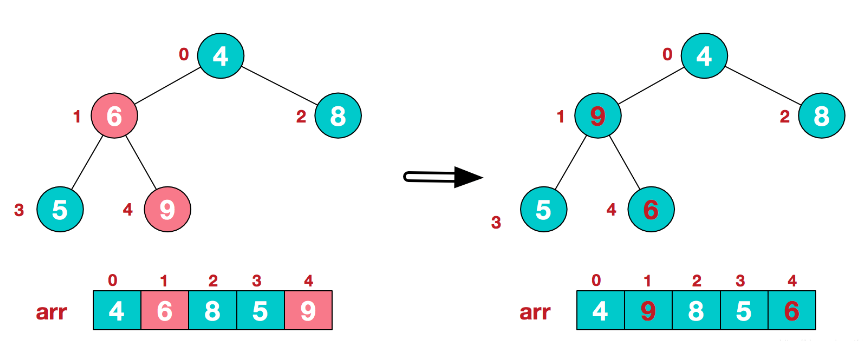


步骤2、交换元素
将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
-
将堆顶元素 9 和末尾元素 4 进行交换。
-
重新调整结构,使其继续满足堆定义。
-
再将堆顶元素 8 与末尾元素 5 进行交换,得到第二大元素 8。
-
后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序。




总结:
- 将无序序列构建成一个堆,根据升序或降序需求选择大顶堆或小顶堆。
- 将堆顶元素与末尾元素交换,最大元素沉到数组末端。
- 重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整和交换步骤,直到整个序列有序。
堆排序的代码实现
代码
1 | package com.jokerdig.tree; |
运行结果
1 | 原始数组:[4, 6, 8, 5, 9] |
经过测试 800万 条随机数排序,堆排序耗费时间大约为 3s 左右;
赫夫曼树的基本介绍
基本介绍
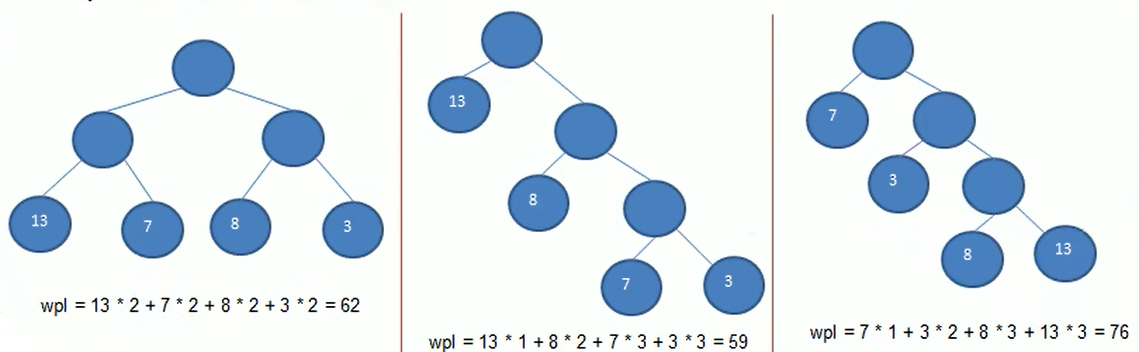
- 给定n个权值作为n个叶子节点,构造一棵二叉树,若该树的带权路径长度(wpl)达到最小,称这样的二叉树为最优二叉树,也称为赫夫曼树(Huffman Tree)。
- 赫夫曼树是带权路径长度最短的树,权值较大的节点离根很近。
举例说明
-
路径和路径长度:在一棵树中,从一个节点往下可以达到的孩子或者孙子节点之间的通路,称为路径;通路中分支的数目称为路径长度。若规定根节点的层数为1,则从根节点到L层节点的路径长度为L-1。
-
节点的权及带权路径长度:若将树中节点赋给一个有着某种含义的数值,则这个数值称为该节点的权。节点的带权路径长度:从根节点到该节点之间的路径长度与该节点的乘积。
-
树的带权路径长度:树的带权路径长度规定为所有叶子节点的带权路径长度之和,记为WPL(weighted path length),权值越大的节点离根节点越近的二叉树才是最优二叉树。
-
WPL最小就是赫夫曼树。

赫夫曼树创建步骤图解
给你一个数组{13,7,8,3,29,6,1},要求转换为一颗赫夫曼树。

步骤分析:
- 从小到大进行排序,每个数据都是一个节点,每个几点可以看成是一棵最简单的二叉树。
- 取出根节点权值最小的两棵二叉树。
- 组成一棵新的二叉树,组成的新二叉树的根节点权值是前面两棵二叉树根节点权值的和。
- 再将这棵新的二叉树,以根节点的权值大小再次排序,不断重复1-2-3-4的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树。
赫夫曼树创建代码实现
代码
1 | package com.jokerdig.huffmanTree; |
运行结果
1 | ========前序遍历赫夫曼树======= |
赫夫曼编码介绍及变长编码举例
基本介绍
- 赫夫曼编码也翻译为哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,属于一种程序算法。
- 赫夫曼编码是赫夫曼树在电讯通信中的经典应用之一。
- 赫夫曼便阿门广泛地用于数据文件压缩。其压缩率通常在20%~90%之间。
- 赫夫曼码是可变字长编码(VLC)的一种,由Huffman于1952年提出的一种编码方式,也称为最佳编码。
原理剖析
在通信领域中信息的处理方式
-
定长编码
- java javascript spring mybatis // 共30个字符(包括空格)
- 106 97 118 97 32 106 97 118 97 115 99 114 105 112 116 32 115 112 114 105 110 103 32 109 121 98 97 116 105 115 // 对应Ascii码(十进制)
- 01101010 01100001 01110110 01100001 00100000 01101010 01100001 01110110 01100001 01110011 01100011 01110010 01101001 01110000 01110100 00100000 01110011 01110000 01110010 01101001 01101110 01100111 00100000 01101101 01111001 01100010 01100001 01110100 01101001 01110011 // 对应二进制
- 按照二进制来传递信息,总长度为319(包括空格)
- 在线转码网站:https://www.rapidtables.org/zh-CN/convert/number/ascii-hex-bin-dec-converter.html
-
变长编码
-
java javascript spring mybatis // 共30个字符(包括空格)
-
c:1 n:1 g:1 m:1 y:1 b:1 j:2 v:2 r:2 p:2 t:2 s:3 i:3 :3 a:5 // 各个字符对应的个数
-
0=a,1= ,10=i,11=s,100=t,101=p,110=r,111=v,1000=j,1001=b,1010=y,1011=m,1100=g,1101=n,1110=c
说明:按照各个字符出现的次数进行编码,原则是出现次数越多,则编码越小;
-
按照上面给的各个字符规定的编码,在传输"java javascript spring mybatis"时,编码为:
1000011101100001110111110110101011001111011101011011100110111010100101001011
-
字符的编码都不能是其它字符编码的前缀,符合此要求的编码叫做前缀编码,即不能匹配到重复的编码;(我们上面的这种方式不符合前缀编码的要求,在解码时可能会出现混乱)
-
赫夫曼编码的原理图解
赫夫曼编码
-
java javascript spring mybatis // 共30个字符(包括空格)
-
c:1 n:1 g:1 m:1 y:1 b:1 j:2 v:2 r:2 p:2 t:2 s:3 i:3 :3 a:5 // 统计各个字符出现的次数
按照上面字符出现的次数构建一棵赫夫曼树,次数作为权值
-
分析图解:
-
我们规定向左为0,向右为1进行编码;
这时候编码分别为:
c:10000 n:10001 g:01110 m:01111
y:01100 b:01101 j:1001 v:1010
r:1011 p:1100 t:1101
s:000 i:001 :010 a:111
我们发现该编码属于前缀编码,每一个编码之间不会冲突;
-
按照上面给的各个字符规定的编码,在传输"java javascript spring mybatis"时,编码为:
1001111101011101010011111010111000100001011001110011010010001100101100110001011100100111101100011011111101001000 // 长度为112
-
长度由原来的319压缩至112,压缩率为:(319-112)/319=61.8% (无损压缩)
-

注意事项
赫夫曼树的根据排序方法的不同,也可能会不太一样,这样对应的赫夫曼编码也完全不一样,但wpl是一样的,都是最小的。
例如:在排序时发现多个权值是相等的,那么在构建过程中相等权值,存放顺序不同,也会导致所构建的赫夫曼树不同。
数据压缩-创建赫夫曼树思路
给出一段文本,比如"java javascript spring mybatis",根据前面的赫夫曼编码原理,对其进行数据压缩处理。
根据赫夫曼编码压缩数据的原理,需要创建"java javascript spring mybatis"对应的赫夫曼树。
步骤分析:
- Node{data{存放数据} ,weight{权值},left和right}。
- 得到"java javascript spring mybatis"对应的byte[]数组。
- 编写一个方法,将准备构建赫夫曼树的Node节点放到List,例如[Node[data=32,weight=3]…]。
- 可以通过List创建对应的赫夫曼树。
数据压缩-创建赫夫曼树实现
代码
1 | package com.jokerdig.huffmanCode; |
运行结果
1 | ======创建的赫夫曼树====== |
数据压缩-生成赫夫曼编码表
思路分析
我们已经生成了赫夫曼树,继续完成任务:
- 生成赫夫曼树对应的赫夫曼编码,如:32=000, 97=111, 98=10110, 99=10111, 103=11000, 105=001, 106=0110, 109=11001, 110=11010, 112=0111, 114=1000, 115=010, 116=1001, 118=1010, 121=11011;
- 使用赫夫曼编码来生成赫夫曼编码数据,即按照上方的赫夫曼编码,将"java javascript spring mybatis"字符串生成对应的编码数据,形式如下:1001111101011101010011111010111000100001011001110011010010001100101100110001011100100111101100011011111101001000;
代码实现
代码
1 | package com.jokerdig.huffmanCode; |
运行结果
1 | ======创建的赫夫曼树====== |
数据压缩-赫夫曼编码字节数组
代码
1 | package com.jokerdig.huffmanCode; |
运行结果
1 | ======创建的赫夫曼树====== |
数据压缩-赫夫曼字节数组封装
代码
1 | package com.jokerdig.huffmanCode; |
运行结果
1 | ======通过赫夫曼编码表压缩数据======= |
数据解压-字节转二进制字符串
思路分析
使用赫夫曼编码来解码数据,具体要求如下:
- 之前我们得到了赫夫曼编码和对应的编码数组byte[],即[111, 92, 55, -82, -81, 5, -28, 39, -125, -84, 12, -18, -34, 74];
- 现在要求使用赫夫曼编码,进行解码,又重新得到原来的字符串"java javascript spring mybatis";
代码实现
代码
1 | // 1. 先将huffmanCodeBytes数组重新转为赫夫曼编码对应二进制字符串 |
数据解压-赫夫曼解码
代码
1 | package com.jokerdig.huffmanCode; |
运行结果
1 | ======通过赫夫曼编码表压缩数据======= |
使用赫夫曼编码压缩文件
思路分析
我们来完成对文件的压缩和解压,要求:给你一个图片文件,要求对其进行无损压缩,并查看压缩效果。
思路:读取文件->得到赫夫曼编码表->完成压缩
代码实现
在D盘存放一张zip.png的图片,初始大小为216KB,压缩后大小为94KB
代码
1 | package com.jokerdig.huffmanCodeZip; |
运行结果
1 | 文件压缩完毕! |
注意:如果你压缩图片后出现大小没变或者压缩后比压缩前还大的问题,可以查看注意事项部分。
使用赫夫曼编码解压文件
思路分析
要求:将之前压缩的文件,重新恢复为原来的文件。
思路:读取压缩文件->完成解压(恢复)
代码实现
代码
1 | package com.jokerdig.huffmanCodeZip; |
运行结果
1 | 文件压缩完毕! |
文件解压后,大小仍然为216KB,没有损失。
赫夫曼编码注意事项
- 如果文件本身就是经过压缩处理的,那么使用赫夫曼编码再压缩效率不会有明显变化,例如:视频,ppt等;
- 赫夫曼编码是按照字节来处理的,因此可以处理所有的文件(如二进制文件,文本文件等);
- 如果一个文件中的内容,重复数据不多,压缩效果也不会很明显;
- 微信
- 支付宝


